Pre-trained language models have led to dramatic advancements in NLP capability in recent years, handily outperforming pipelined systems and non-contextual embeddings on most common tasks. What makes them so powerful? As a model like BERT learns to fill in blanks or predict the next word, what kind of linguistic or world knowledge does it acquire? How is this information organized: does the model learn the same rules a human might, or develop it’s own idiosyncratic understanding? And: how is this information used, if such a model is asked to classify text, answer questions, or perform other downstream NLP tasks?
For an excellent primer on what we do - and don’t - know in this space, also see A Primer in BERTology: What We Know About How BERT Works (Rogers et al. 2020).
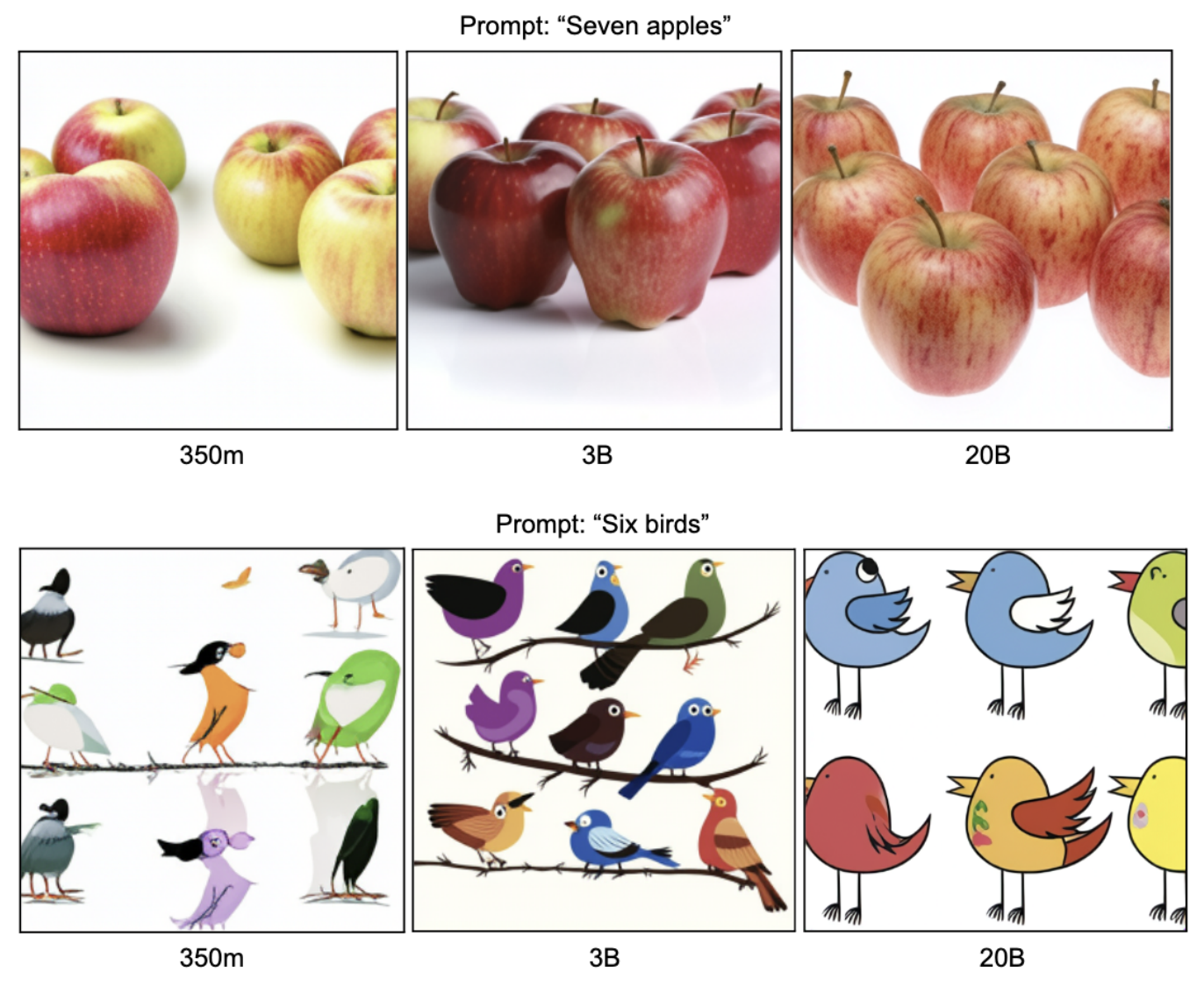
Can Generative Multimodal Models Count to Ten?
Sunayana Rane,
Alexander Ku,
Jason Michael Baldridge,
Ian Tenney,
Thomas L. Griffiths,
and Been Kim
In Proceedings of the Annual Meeting of the Cognitive Science Society,
2024
The creation of sophisticated AI systems that are able to process and produce images and text creates new challenges in assessing the capabilities of those systems. We adapt a behavioral paradigm from developmental psychology to characterize the counting ability of a model that generates images from text. We show that three model scales of the Parti model (350m, 3B, and 20B parameters respectively) each have some counting ability, with a significant jump in performance between the 350m and 3B model scales. We also demonstrate that it is possible to interfere with these models’ counting ability simply by incorporating unusual descriptive adjectives for the objects being counted into the text prompt. We analyze our results in the context of the knower-level theory of child number learning. Our results show that we can gain experimental intuition for how to probe model behavior by drawing from a rich literature of behavioral experiments on humans, and, perhaps most importantly, by adapting human developmental benchmarking paradigms to AI models, we can characterize and understand their behavior with respect to our own.
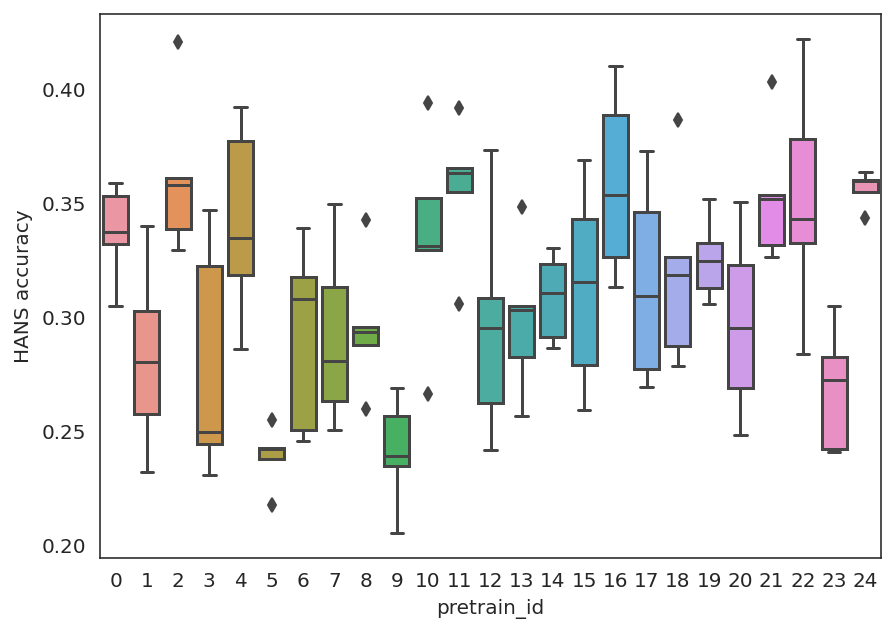
The MultiBERTs: BERT Reproductions for Robustness Analysis
Thibault Sellam,
Steve Yadlowsky,
Ian Tenney,
Jason Wei,
Naomi Saphra,
Alexander D’Amour,
Tal Linzen,
Jasmijn Bastings,
Iulia Turc,
Jacob Eisenstein,
Dipanjan Das,
and Ellie Pavlick
ICLR (spotlight),
2022
Experiments with pre-trained models such as BERT are often based on a single checkpoint. While the conclusions drawn apply to the artifact tested in the experiment (i.e., the particular instance of the model), it is not always clear whether they hold for the more general procedure which includes the architecture, training data, initialization scheme, and loss function. Recent work has shown that repeating the pre-training process can lead to substantially different performance, suggesting that an alternative strategy is needed to make principled statements about procedures. To enable researchers to draw more robust conclusions, we introduce MultiBERTs, a set of 25 BERT-Base checkpoints, trained with similar hyper-parameters as the original BERT model but differing in random weight initialization and shuffling of training data. We also define the Multi-Bootstrap, a non-parametric bootstrap method for statistical inference designed for settings where there are multiple pre-trained models and limited test data. To illustrate our approach, we present a case study of gender bias in coreference resolution, in which the Multi-Bootstrap lets us measure effects that may not be detected with a single checkpoint. The models and statistical library are available online, along with an additional set of 140 intermediate checkpoints captured during pre-training to facilitate research on learning dynamics.
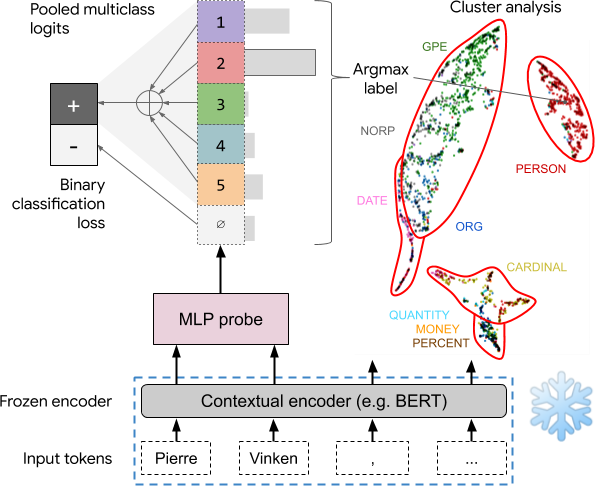
Asking without Telling: Exploring Latent Ontologies in Contextual Representations
Julian Michael,
Jan A. Botha,
and Ian Tenney
In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP),
2020
The success of pretrained contextual encoders, such as ELMo and BERT, has brought a great deal of interest in what these models learn: do they, without explicit supervision, learn to encode meaningful notions of linguistic structure? If so, how is this structure encoded? To investigate this, we introduce latent subclass learning (LSL): a modification to classifier-based probing that induces a latent categorization (or ontology) of the probe’s inputs. Without access to fine-grained gold labels, LSL extracts emergent structure from input representations in an interpretable and quantifiable form. In experiments, we find strong evidence of familiar categories, such as a notion of personhood in ELMo, as well as novel ontological distinctions, such as a preference for fine-grained semantic roles on core arguments. Our results provide unique new evidence of emergent structure in pretrained encoders, including departures from existing annotations which are inaccessible to earlier methods.
Do Language Embeddings capture Scales?
Xikun Zhang,
Deepak Ramachandran,
Ian Tenney,
Yanai Elazar,
and Dan Roth
In Findings of the Association for Computational Linguistics: EMNLP,
2020
Pretrained Language Models (LMs) have been shown to possess significant linguistic, common sense and factual knowledge. One form of knowledge that has not been studied yet in this context is information about the scalar magnitudes of objects. We show that pretrained language models capture a significant amount of this information but are short of the capability required for general common-sense reasoning. We identify contextual information in pre-training and numeracy as two key factors affecting their performance, and show that a simple method of canonicalizing numbers can have a significant effect on the results.
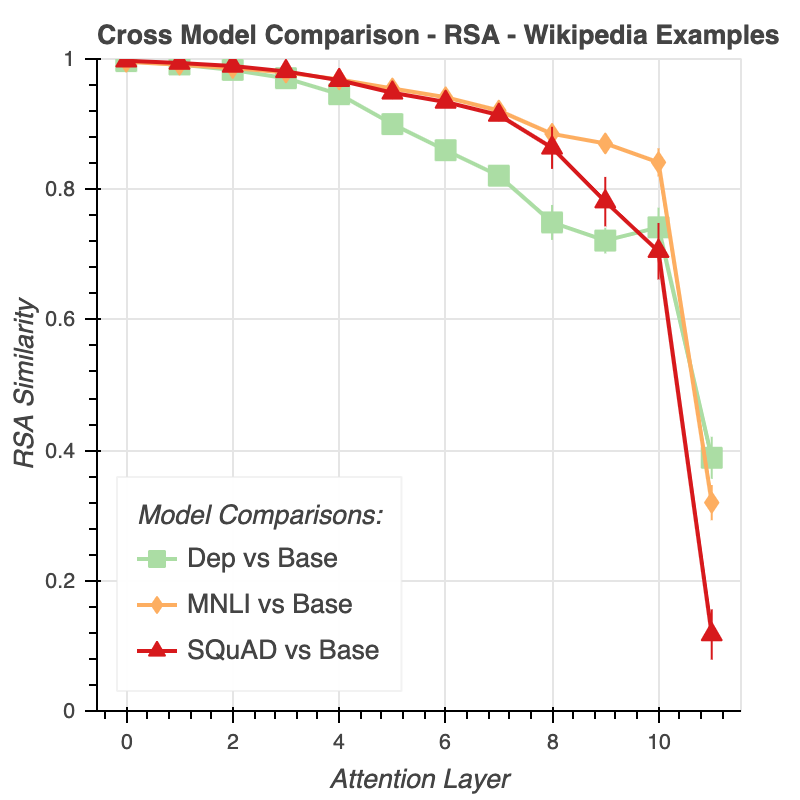
What Happens To BERT Embeddings During Fine-tuning?
Amil Merchant,
Elahe Rahimtoroghi,
Ellie Pavlick,
and Ian Tenney
In Proceedings of the Third BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP,
2020
While much recent work has examined how linguistic information is encoded in pre-trained sentence representations, comparatively little is understood about how these models change when adapted to solve downstream tasks. Using a suite of analysis techniques—supervised probing, unsupervised similarity analysis, and layer-based ablations—we investigate how fine-tuning affects the representations of the BERT model. We find that while fine-tuning necessarily makes some significant changes, there is no catastrophic forgetting of linguistic phenomena. We instead find that fine-tuning is a conservative process that primarily affects the top layers of BERT, albeit with noteworthy variation across tasks. In particular, dependency parsing reconfigures most of the model, whereas SQuAD and MNLI involve much shallower processing. Finally, we also find that fine-tuning has a weaker effect on representations of out-of-domain sentences, suggesting room for improvement in model generalization.
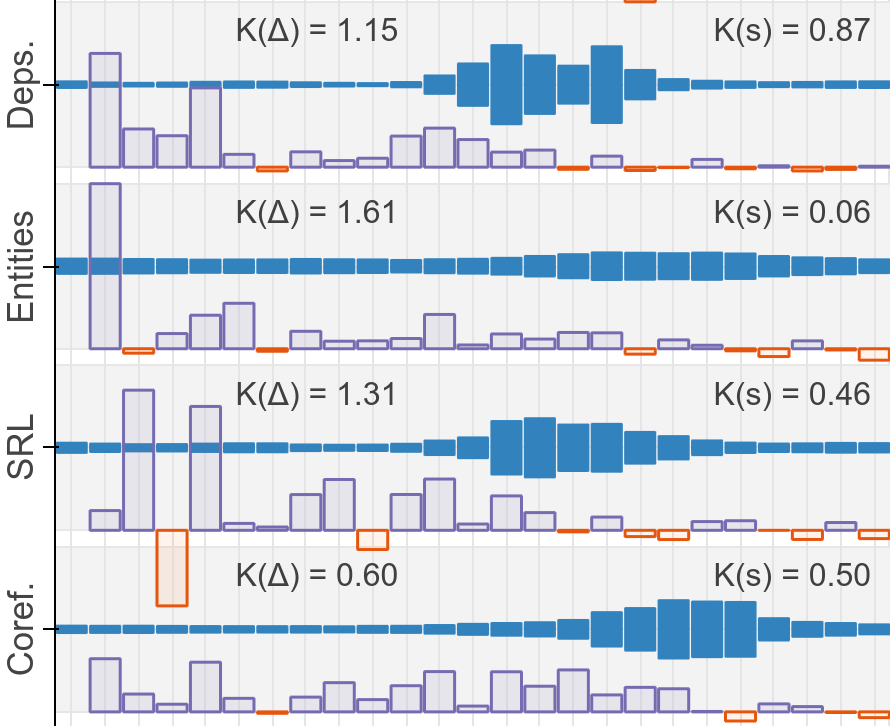
BERT Rediscovers the Classical NLP Pipeline
Ian Tenney,
Dipanjan Das,
and Ellie Pavlick
In Proceedings of the 57th Conference of the Association for Computational Linguistics,
2019
Pre-trained text encoders have rapidly advanced the state of the art on many NLP tasks. We focus on one such model, BERT, and aim to quantify where linguistic information is captured within the network. We find that the model represents the steps of the traditional NLP pipeline in an interpretable and localizable way, and that the regions responsible for each step appear in the expected sequence: POS tagging, parsing, NER, semantic roles, then coreference. Qualitative analysis reveals that the model can and often does adjust this pipeline dynamically, revising lower-level decisions on the basis of disambiguating information from higher-level representations.
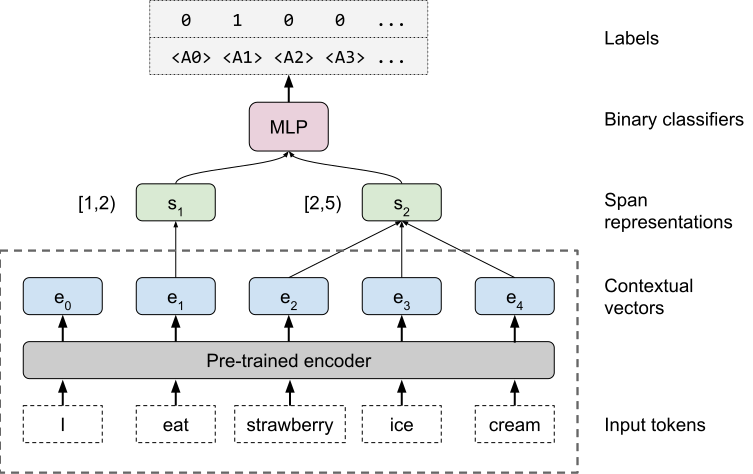
What do you learn from context? Probing for sentence structure in contextualized word representations
Ian Tenney,
Patrick Xia,
Berlin Chen,
Alex Wang,
Adam Poliak,
R Thomas McCoy,
Najoung Kim,
Benjamin Van Durme,
Sam Bowman,
Dipanjan Das,
and Ellie Pavlick
In International Conference on Learning Representations,
2019
Contextualized representation models such as ELMo (Peters et al., 2018a) and BERT (Devlin et al., 2018) have recently achieved state-of-the-art results on a diverse array of downstream NLP tasks. Building on recent token-level probing work, we introduce a novel edge probing task design and construct a broad suite of sub-sentence tasks derived from the traditional structured NLP pipeline. We probe word-level contextual representations from four recent models and investigate how they encode sentence structure across a range of syntactic, semantic, local, and long-range phenomena. We find that existing models trained on language modeling and translation produce strong representations for syntactic phenomena, but only offer comparably small improvements on semantic tasks over a non-contextual baseline.
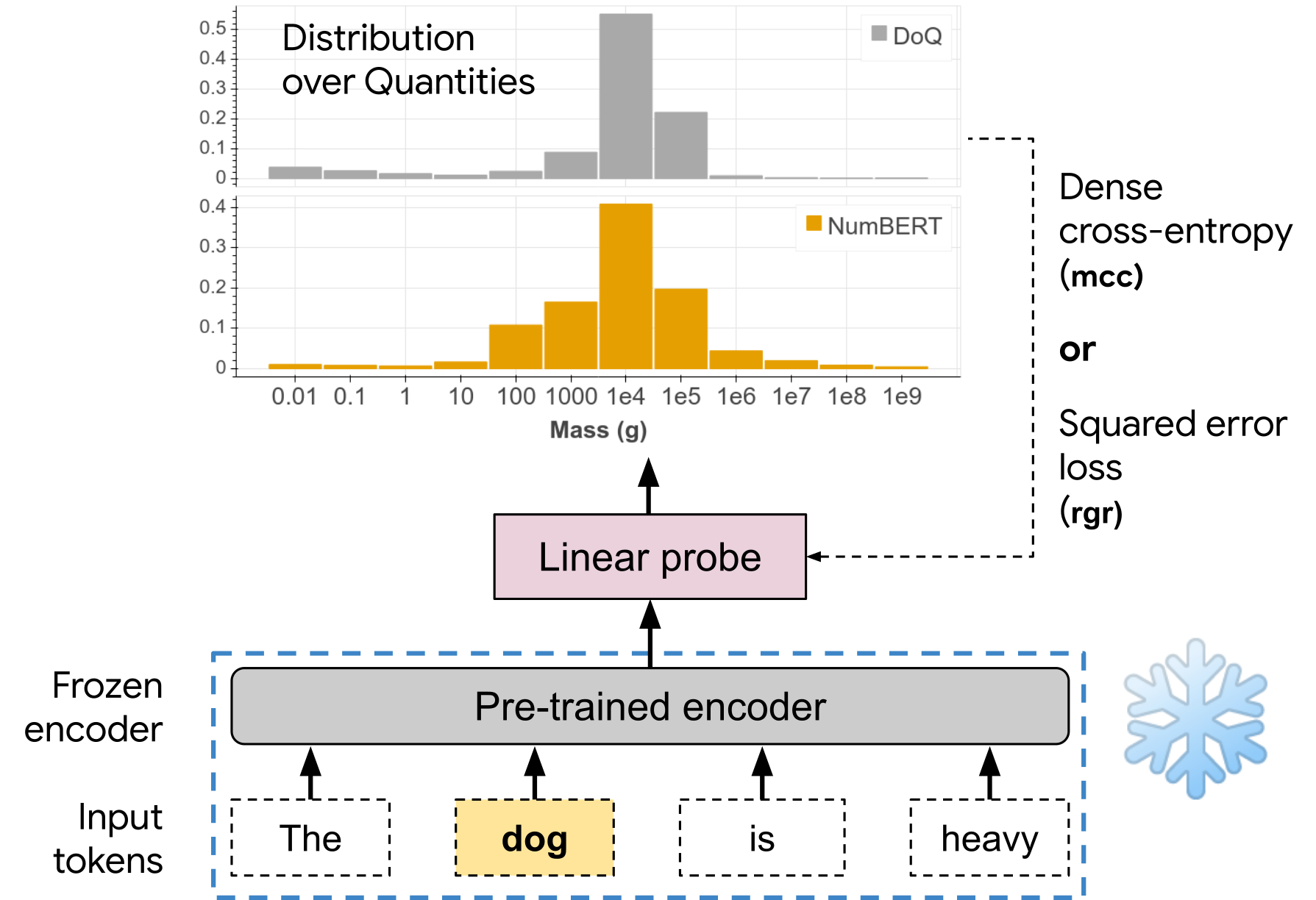 Do Language Embeddings capture Scales?In Findings of the Association for Computational Linguistics: EMNLP, 2020
Do Language Embeddings capture Scales?In Findings of the Association for Computational Linguistics: EMNLP, 2020