Training Data Attribution (TDA) aims to explain model behavior in terms of specific examples from the data it was trained on. For classification or another supervised task this might be labeled (input, output) pairs, while for a language model these could be segments of running text from the pretraining corpus.
In theory, data attribution could be computed by simply making a change to the training set - such as removing an example - then re-training the model and seeing how its behavior changes. This is computationally expensive, however, so TDA methods allow us to approximate this in an efficient manner.
Scalable Influence and Fact Tracing for Large Language Model Pretraining
Tyler A. Chang,
Dheeraj Rajagopal,
Tolga Bolukbasi,
Lucas Dixon,
and Ian Tenney
ICLR,
2025
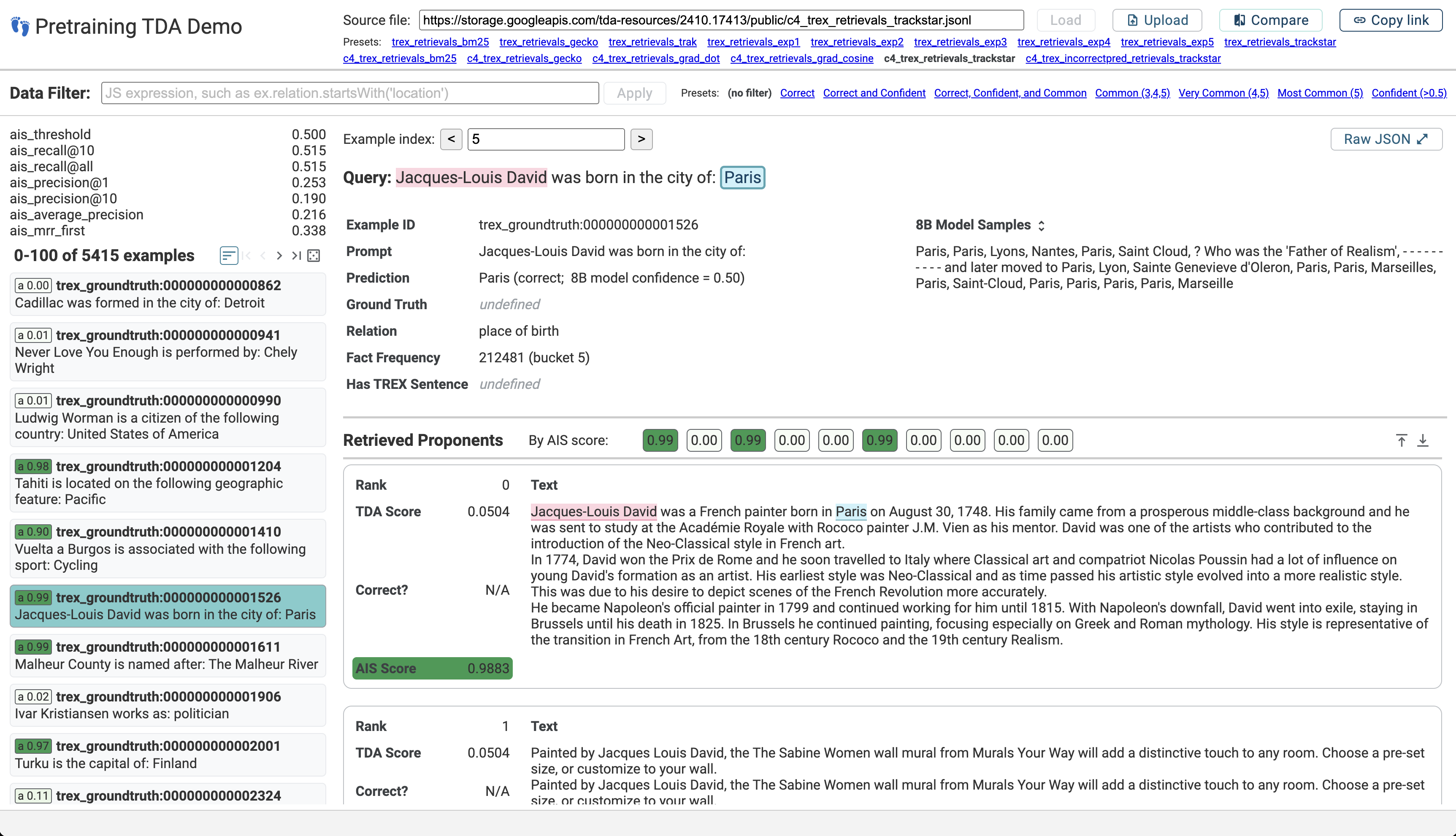
Training data attribution (TDA) methods aim to attribute model outputs back to specific training examples, and the application of these methods to large language model (LLM) outputs could significantly advance model transparency and data curation. However, it has been challenging to date to apply these methods to the full scale of LLM pretraining. In this paper, we refine existing gradient-based methods to work effectively at scale, allowing us to retrieve influential examples for an 8B-parameter language model from a pretraining corpus of over 160B tokens with no need for subsampling or pre-filtering. Our method combines several techniques, including optimizer state correction, a task-specific Hessian approximation, and normalized encodings, which we find to be critical for performance at scale. In quantitative evaluations on a fact tracing task, our method performs best at identifying examples that influence model predictions, but classical, model-agnostic retrieval methods such as BM25 still perform better at finding passages which explicitly contain relevant facts. These results demonstrate a misalignment between factual attribution and causal influence. With increasing model size and training tokens, we find that influence more closely aligns with attribution. Finally, we examine different types of examples identified as influential by our method, finding that while many directly entail a particular fact, others support the same output by reinforcing priors on relation types, common entities, and names.
Simfluence: Modeling the Influence of Individual Training Examples by Simulating Training Runs
Kelvin Guu,
Albert Webson,
Ellie Pavlick,
Lucas Dixon,
Ian Tenney,
and Tolga Bolukbasi
arXiv preprint,
2023
Training data attribution (TDA) methods offer to trace a model’s prediction on any given example back to specific influential training examples. Existing approaches do so by assigning a scalar influence score to each training example, under a simplifying assumption that influence is additive. But in reality, we observe that training examples interact in highly non-additive ways due to factors such as inter-example redundancy, training order, and curriculum learning effects.
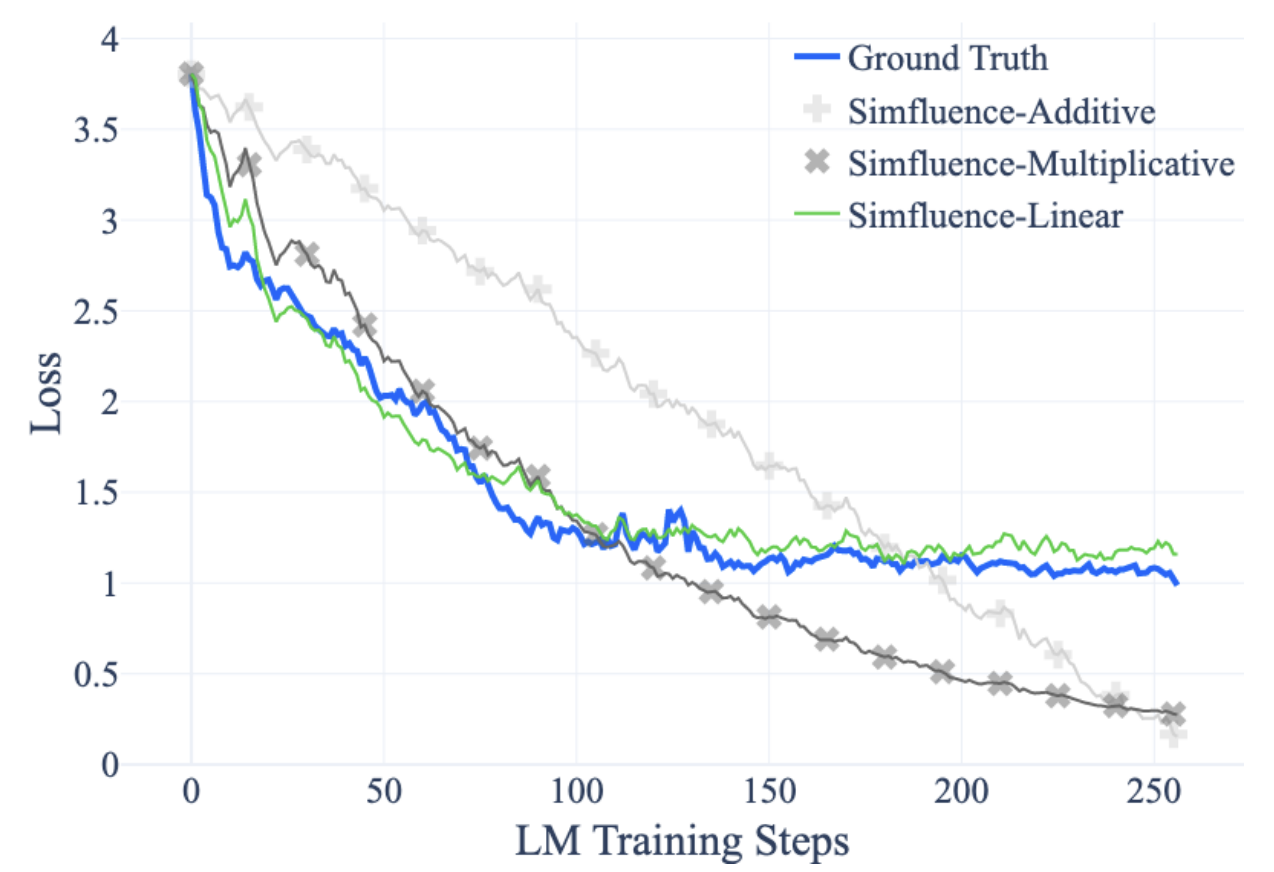
To study such interactions, we propose Simfluence, a new paradigm for TDA where the goal is not to produce a single influence score per example, but instead a training run simulator: the user asks, “If my model had trained on example z1, then z2, ..., then zn, how would it behave on ztest?”; the simulator should then output a simulated training run, which is a time series predicting the loss on ztest at every step of the simulated run. This enables users to answer counterfactual questions about what their model would have learned under different training curricula, and to directly see where in training that learning would occur.
We present a simulator, Simfluence-Linear, that captures non-additive interactions and is often able to predict the spiky trajectory of individual example losses with surprising fidelity. Furthermore, we show that existing TDA methods such as TracIn and influence functions can be viewed as special cases of Simfluence-Linear. This enables us to directly compare methods in terms of their simulation accuracy, subsuming several prior TDA approaches to evaluation. In experiments on large language model (LLM) fine-tuning, we show that our method predicts loss trajectories with much higher accuracy than existing TDA methods (doubling Spearman’s correlation and reducing mean-squared error by 75%) across several tasks, models, and training methods.
Tracing Knowledge in Language Models Back to the Training Data
Ekin Akyürek,
Tolga Bolukbasi,
Frederick Liu,
Binbin Xiong,
Ian Tenney,
Jacob Andreas,
and Kelvin Guu
In Findings of the Association for Computational Linguistics: EMNLP,
2022
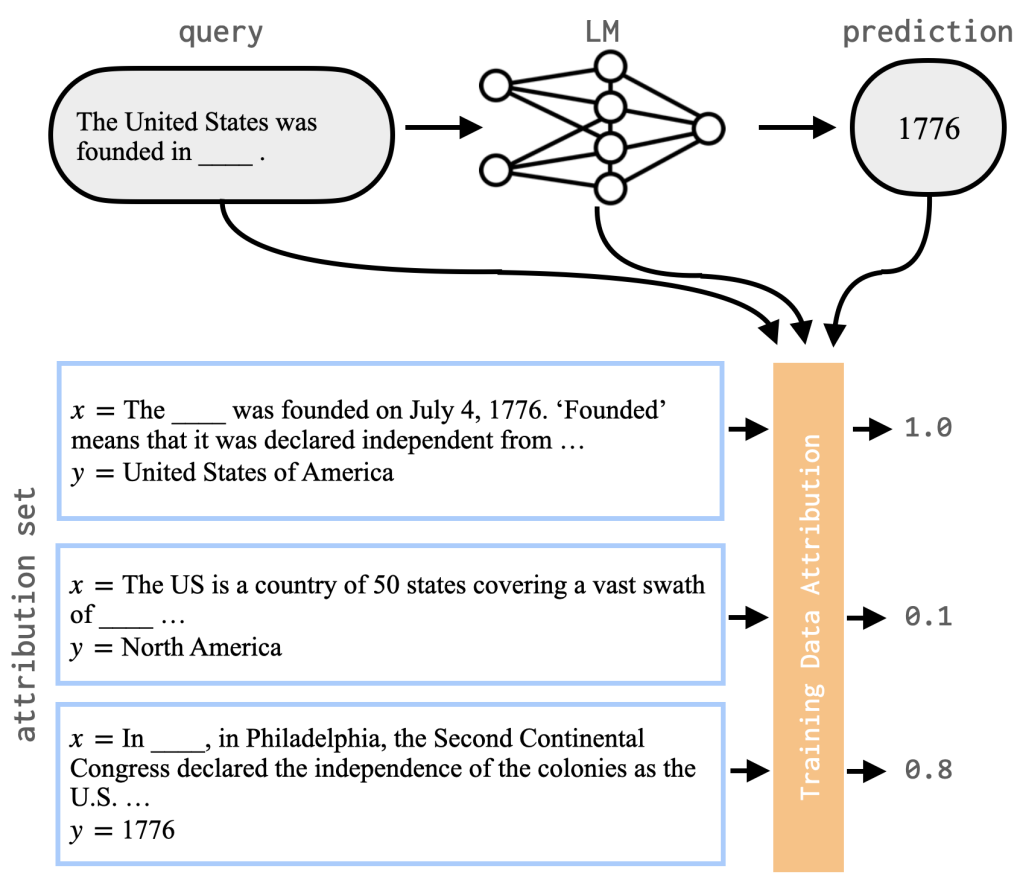
Language models (LMs) have been shown to memorize a great deal of factual knowledge contained in their training data. But when an LM generates an assertion, it is often difficult to determine where it learned this information and whether it is true. In this paper, we propose the problem of fact tracing: identifying which training examples taught an LM to generate a particular factual assertion. Prior work on training data attribution (TDA) may offer effective tools for identifying such examples, known as "proponents". We present the first quantitative benchmark to evaluate this. We compare two popular families of TDA methods – gradient-based and embedding-based – and find that much headroom remains. For example, both methods have lower proponent-retrieval precision than an information retrieval baseline (BM25) that does not have access to the LM at all. We identify key challenges that may be necessary for further improvement such as overcoming the problem of gradient saturation, and also show how several nuanced implementation details of existing neural TDA methods can significantly improve overall fact tracing performance.